classInteger:
def __init__(self, x):
self.x = x
def_rc(self, x):
return self.__class__(x)
def __iadd__(self, other):
if type(other) == __class__:
self.x = self.x + other.x
else:
self.x = self.x + other
return self
def __add__(self, other):
return self._rc(self.x + other.x)
def __str__(self):
return"{}".format(self.x)
a = Integer(10)
print(id(a), a) # 140267813136872 10
a = a + Integer(2)
print(id(a), a) # 140267813137096 12
a +=3print(id(a), a) # 140267813137096 15
+= 연산자를 오버로딩하는 메소드는 iadd 메소드, + 연산자는 add 메소드이다.
Numpy 와 비슷하게 동작하게끔 하기 위해서, 의도적으로 이 두개를 다르게 만들었다.
20번 23번 줄을 보면 같은 id 인 것을 볼 수 있다.
id(a) 함수는 객체의 참조값을 리턴한다. C 언어의 포인터와 비슷하다.
객체의 id 값은 unique 하다. 두 객체가 같은 id 를 가지고 있다면 객체는 같은 참조를 가르킨다.
실제 id 값은 실행할 때마다 다를 수 있다. 프로그램 내에서 이 값이 변하는지, 안 변하는지가 중요하다.
다른 예제로
예제 1. numpy
1
2
3
4
import numpy as np
a = np.arange(3)
a = a +1print(a) # [1 2 3]
_
1
2
3
4
import numpy as np
a = np.arange(3)
a +=1print(a) # [1 2 3]
위 두개의 모두 a 의 값은 같다.
예제 2. numpy 배열 일부 치환
1
2
3
4
5
6
import numpy as np
x = np.arange(6)
y = x[1:3]
y = y +1print(x) # [0 1 2 3 4 5]print(y) # [2 3]
_
1
2
3
4
5
6
import numpy as np
x = np.arange(6)
y = x[1:3]
y +=1print(x) # [0 2 3 3 4 5]print(y) # [2 3]
위 아래 결과의 출력 값이 다르다. id 를 찍어보면 좀 더 명확해진다.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.arange(6)
y = x[1:3]
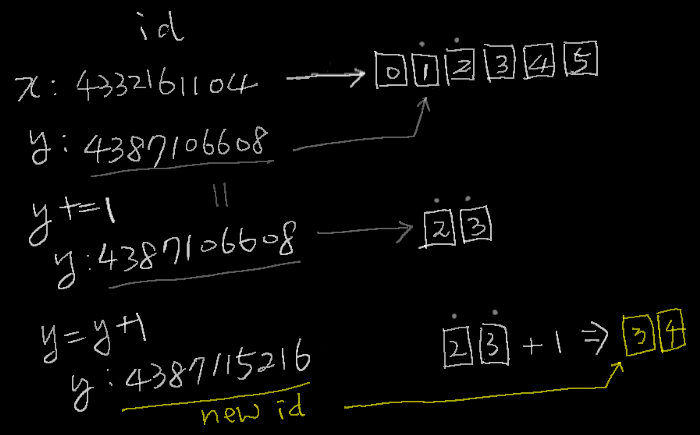
print(id(x), x) # 4332161104 [0 1 2 3 4 5]print(id(y), y) # 4387106608 [1 2]
y +=1print(id(x), x) # 4332161104 [0 2 3 3 4 5]print(id(y), y) # 4387106608 [2 3]
y = y +1print(id(x), x) # 4332161104 [0 2 3 3 4 5]print(id(y), y) # 4387115216 [3 4]
그림을 그려보면 좀 더 쉽게 이해할 수 있다.
y += 1 과 y = y + 1 이 다르게 동작함을 다시 한번 확인할 수 있다.
예제 3. built-in type
1
2
3
4
5
6
7
8
9
# integer example
x =10
y =10print(id(x), x) # 4557295680 10print(id(y), y) # 4557295680 10
x +=1print(id(x), x) # 4557295712 11
x = x +1print(id(x), x) # 4557295744 12
두 integer 변수 x, y 의 값이 같으면 id 도 같다.
1
2
3
4
5
6
7
8
9
# string example 1
s ='xyz'
t ='xyz'print(id(s), s) # 4437129008 xyzprint(id(t), t) # 4437129008 xyz
t +='123'print(id(t), t) # 4437389104 xyz123t = t +'123'print(id(t), t) # 4437389104 xyz123123
문자열을 참조하는 두 변수 s, t 는 같은 id 를 갖는다. 즉 같은 참조를 가르킨다.
그런데 7번째 줄과 9번째 줄을 보면 id 는 같지만 문자열이 다르다.
numpy 객체 예에서는 += 의 경우 id 는 바뀌지 않았고, + 의 경우 바뀌었다.
문자열 객체 예에서는 반대다.
조금만 코드를 수정해 보자.
1
2
3
4
5
6
7
8
9
10
# string example 2
t ='xyz'print(id(t), t) # 4451686384 xyz
t +='123'
tt = t
print(id(t), t) # 4452413296 xyz123print(id(tt), tt) # 4452413296 xyz123
t = t +'123'print(id(t), t) # 4452413168 xyz123123print(id(tt), tt) # 4452413296 xyz123
6번째 9번째 줄을 보면, 이제는 “+=” 연산자, “+” 연산자 모두 id 값이 바뀐다.
추측컨데 [String example 1] 8번째 줄 t = t + ‘123’ 를 수행할 때 기존의 t 의 참조가 더이상 필요하지 않기 때문에
t 의 id 를 재활용한 것으로 생각해 볼 수 있다. [String example 2] 5번째 줄에서 tt 변수가 참조를 가지고 있으므로
8번째 줄을 수행할 때 t 에는 새로운 id 가 할당된다고 볼 수 있을 것이다.